EL viernes 19 de julio del 2024 se vivió un apagón informático por un error en la actualización de un sistema antivirus sin precedente. Lo más terrible antes de esto se dio cuando sucedió el ataque del ransomware #WannaCry en mayo del 2017. La crisis afectó a numerosas empresas a nivel mundial y ciberdelincuentes aprovecharon la situación para generar ciberataques.
Más de 230 mil equipos se vieron afectadas en pocas horas alrededor de 179 países y generó millonarias pérdidas ya que afectó desde hospitales hasta operadores de telecomunicaciones. Según un análisis de Bitdefender, el pago de estos rescates alcanzó ese año los US$2000 millones.
Otros proveedores cloud también han tenido problemas. Por ejemplo, el servicio de almacenamiento S3 de Amazon Web Services (AWS), líder del mercado, en marzo del 2017 sufrió altas tasas de error, causando interrupciones en muchas web y aplicaciones (Quora, Business Insider y Slack). En noviembre del 2020 otro apagón significativo afectó a una gran cantidad de servicios que dependen de AWS.





Otro caso sonado sucedió en octubre de 2021, cuando se cayó Facebook, WhatsApp, Instagram y Messenger por casi seis horas debido a un cambio de configuración defectuoso en los routers que comunicaban sus centros de datos, afectando a miles de millones de usuarios. Pero el viernes 19 de julio se superaron con creces todos estos eventos anteriores.
¿Qué pasó exactamente?
La alerta de seguridad emitida por el Centro Nacional de Seguridad Digital (CNSD) del Perú informó que el problema, calificado como severidad CRÍTICA, está relacionada con el sensor Falcon de CrowdStrike y afectó a varias estaciones de trabajo y servidores. Los síntomas incluyeron reinicios inesperados, congelamientos y las temidas pantallas azules.
La solución de seguridad CrowdStrike tuvo un fallo el 19 de julio al actualizar el sensor Falcon de la compañía, que, si bien se instala en varios sistemas operativos, en esta oportunidad el problema afectó solo a Windows, por un error en el código.
Más de 230 mil equipos se vieron afectadas en pocas horas alrededor de 179 países y generó millonarias pérdidas ya que afectó desde hospitales hasta operadores de telecomunicaciones.
La compañía informó que fue un defecto en una actualización de contenido para hosts de Windows, no para Mac, ni para Linux. Tampoco afectaba a las PC de los usuarios domésticos, porque se trata de un problema para usuarios corporativos.
¿Fue en realidad solo en Windows?
Sí, pero no. El portal HardZone informó que usuarios de Linux, especialmente de la distribución Debian, se estaban quejando de problemas y bloqueos de kernel relacionados con CrowdStrike desde abril. Fueron problemas aislados no relacionados con el caótico suceso que sacudió el mundo el pasado 19 de julio, pero demuestran que ya había disconformidades con el servicio.
Al tratarse de un software de seguridad que funciona a nivel de kernel del sistema, es decir, que se integra en el propio sistema operativo, es vital hacer un trabajo cuidadoso, algo que estiman los expertos que no estaba sucediendo algunos meses atrás. Además, trascendió que el mismo Microsoft había tenido ya algunas quejas y disconformidades con el proveedor, por lo que esto fue la gota – o el diluvio – que derramó el vaso.
La solución de seguridad CrowdStrike tuvo un fallo el 19 de julio al actualizar el sensor Falcon de la compañía, que, si bien se instala en varios sistemas operativos, en esta oportunidad el problema afectó solo a Windows, por un error en el código.
¿Cómo se reparaba?
El día del incidente, CrowdStrike indicó que, como no se podían recibir las actualizaciones automáticamente, había que realizar una intervención manual en modo de recuperación de Windows para solucionar el problema. Eso fue tedioso porque implicaba que un técnico, con los permisos adecuados por temas de seguridad (clave de cifrado, en algunos casos), fuera reiniciando y borrando la actualización problemática en cada equipo colgado.
Era aplicar un workaround, es decir una solución temporal alternativa para que las empresas pudieran seguir operando hasta darse la solución definitiva. En algunos casos, Microsoft advirtió que podían ser necesarios varios reinicios (se han reportado hasta 15), pero ese era sin duda el camino efectivo de solución temporal.
¿Se solucionó por completo el problema?
CrowdStrike anunció en su página web que identificó el error e implementó una solución. Los usuarios que no podían permanecer en línea para recibir los “cambios en el archivo” tenían que aplicar la solución uno a uno, ya mencionada, de reinicio. ¿Basta con eso? Para el momento de la crisis sí, pero los encargados de sistemas aún están un poco al sobresalto y alertas ante cualquier nuevo aviso de actualización del sistema.
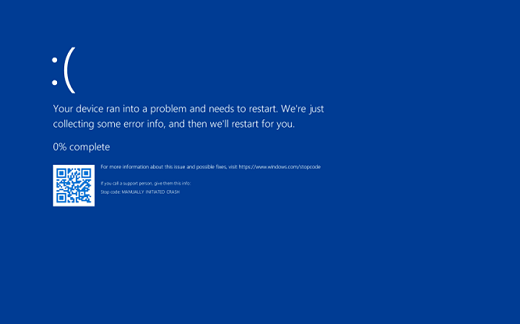
Microsotf informó la noche del domingo que: “Estamos al tanto de un problema que comenzó el 19 de julio de 2024 a las 04:09 UTC, que provocó que los clientes experimentaran falta de respuesta y fallas de inicio en las máquinas Windows que usaban el agente CrowdStrike Falcon, lo que afectó tanto a las plataformas locales como a varias plataformas en la nube. Para obtener opciones de recuperación adicionales, consulte https://aka.ms/CSfalcon-VMRecoveryOptions”.
Para ayudar a sus clientes, Microsoft además de desplegar personal, lanzó una herramienta de recuperación para reparar las máquinas afectadas que recibieron la actualización defectuosa de CrowdStrike. Se obtiene desde el Centro de descarga de Microsoft, se pone en una USB y permite eliminar el archivo problemático de CrowdStrike sin tener los derechos de administrador del dispositivo, algo que entorpecía el proceso de recuperación, informó el medio de comunicación y noticias mexicano Expansión.
¿Quiénes fueron los afectados?
La falla global provocada por la actualización de CrowdStrike en equipos con Windows afectó a unos 8,5 millones de dispositivos, según Microsoft. Aunque esto representa “menos del 1% de todas las máquinas Windows”, el impacto fue calamitoso porque grandes compañías que poseen miles de usuarios dejaron de funcionar. Hablamos de más de 5000 vuelos estancados el día 19 en la mañana y luego una larga cadena de retrasos y reprogramaciones en todo el mundo durante 48 horas, y esto solo observando el rubro aerolíneas.
Para ayudar a sus clientes, Microsoft además de desplegar personal, lanzó una herramienta de recuperación para reparar las máquinas afectadas que recibieron la actualización defectuosa de CrowdStrike.
Si observamos el sector salud tenemos que CNN informó que en la noche previa y la madrugada del viernes varios estados, entre ellos Alaska y Arizona, sufrieron interrupciones del servicio 911. Además, fallaron los sistemas en varios hospitales.
Varios centros oncológicos, como el Dana-Farber de Boston y el Memorial Sloan Kettering de Nueva York, informaron en la mañana del viernes que suspendieron algunos procedimientos y citas programadas. Hasta hubo inconvenientes en el reparto de sangre del New York Blood Center, proveedor de unos 200 hospitales del noreste de Estados Unidos.
Bancos de todo el mundo arrancaron la mañana con problemas. Entre ellos estaba el Commonwealth Bank de Australia, el Capitec de Sudáfrica y el Banco de Israel. También se afectó el ASB Bank de Nueva Zelandia y los prestamistas australianos ANZ y Westpac, según CNN informó citando a Downdetector, un sitio web que rastrea las interrupciones cibernéticas.
La falla global provocada por la actualización de CrowdStrike en equipos con Windows afectó a unos 8,5 millones de dispositivos, según Microsoft.
El caos llegó a empresas de mensajería UPS y FedEx, minoristas, sistemas de pago, oficinas administrativas de los Gobiernos, sistemas de información de transporte público y todo un largo etcétera que alimentó a las redes sociales para la creación de memes y fotografías atípicas.
El apagón escaló a dimensiones dantescas. Y la nota curiosa es que quienes no tenían sistemas modernos, como por ejemplo la aerolínea Southwest Airlines, quien no había actualizado su versión de Windows en unas dos décadas, se salvaron de quedarse colgados.
En América Latina y el Perú no fue tan dramático porque cuando acá empezaba el día ya en otras partes del mundo se tenían horas armando planes de acción y ya se tenían más luces sobre los caminos para paliar el problema, que había empezado en Australia y Asia. Latam Airlines tuvo algunos inconvenientes, pero el grueso de afectados sobre todo estuvo en los retrasos en las interconexiones en las siguientes 48 horas.




¿Han surgido más complicaciones?
La historia no ha terminado. Además de las actualizaciones, el otro gran dolor de cabeza del área de sistemas es que comenzaron a surgir verdaderos ciberataques aprovechando el ruido en torno al tema. Según la unidad de investigación de SILIKN, informó en Computer Weekly que los ciberdelincuentes armaron rápidamente campañas de phishing y lanzaron ataques de ingeniería social suplantando la identidad de CrowdStrike y ofreciendo un falso parche de seguridad. Los fines eran los habituales en estos casos: robar información, accesos no autorizados o secuestrar datos.
Los ciberdelincuentes están buscando en foros clandestinos código malicioso que pueda aprovechar esta falla. Se está pidiendo y pagando por esas herramientas. Por eso se recomienda estar atentos sólo a las comunicaciones oficiales de CrowdStrike o Microsoft para no ser víctimas de alguna de estas campañas maliciosas.
¿Cuál fue el costo del incidente?
Solo para CrowdStrike, el costo fue mayúsculo. Con entre 24 mil y 30 mil suscriptores, su valor de mercado bordeaba los US$80 mil millones y ese día, tras el incidente, cayo un 11% el valor de la acción, llegando a un 23% poco después. Para los inversionistas era evidente que faltó un buen control de calidad, cuando menos, para evitar este apagón. El Dr. Erick Iriarte Ahon, CEO de eBIZ, recalcó que es importante tener un sistema de verificación de las actualizaciones bien cuidado, porque la falla humana siempre es posible.
En América Latina y el Perú no fue tan dramático porque cuando acá empezaba el día ya en otras partes del mundo se tenían horas armando planes de acción y ya se tenían más luces sobre los caminos para paliar el problema.
En cambio, las acciones de Microsoft cayeron solo entre 1,66% y 3,43%, porque entre los inversionistas fue percibido solo como uno de los afectados y no la causa del gran problema, porque aun cuando también hubo una falla en la nube de Azure en la noche del jueves que produjo un apagón, esto no estaría relacionado con el mega desastre del viernes.
Entre ambas empresas se estima que habrían llegado a perder en valores de acciones unos S/ 2,90 mil millones (US$7,6 mil millones) debido al apagón informático. Pero es muy pronto para tener un cálculo exacto porque solo ha pasado poco tiempo.
Aunque las acciones se estabilizaron, para CrowdStrike la pesadilla no ha terminado, porque es muy probable que tenga que asumir demandas legales millonarias. Ya sea por parte del mismo Microsoft, como de los clientes corporativos que usan Windows. Y no olvidemos a los consumidores de dichas compañías, que perdieron tiempo y dinero: miles de millones de dólares que aún no han sido calculados o difundidos.
Solo para CrowdStrike, el costo fue mayúsculo. Con entre 24 mil y 30 mil suscriptores, su valor de mercado bordeaba los US$80 mil millones y ese día, tras el incidente, cayo un 11% el valor de la acción, llegando a un 23% poco después.
Entre los principales rivales de CrowdStrike, que tiene un 17% del mercado, están Palo Alto Networks, SentinelOne y Fortinet, quienes han visto efectos positivos en el valor de sus acciones, además de que, a la larga, pueden ganar algunos clientes. Durante la interrupción en los servicios de CrowdStrike, las acciones de ellas subieron: Palo Alto Networks ganó un 2,16%, SentinelOne se elevó un 7,85% y Fortinet un 0,6%.
Pablo Creus comentó en el portal LisaNews que George Kurtz, cofundador y CEO de CrowdStrike, sufrió una pérdida de US$ 320 millones tras el desplome de las acciones de la empresa. Pero ese no es su único problema. Blomberg informó que el Comité de Seguridad Nacional de la Cámara de Representantes del Congreso estadounidense solicitó su comparecencia y pidió fijen una fecha para que acuda a explicar qué ocurrió y qué se está haciendo para que no vuelva a pasar.
Recodemos que no es la primera vez que George Kurtz está ligado a una catástrofe informática: era CTO de McAFee en abril del 2010, cuando una actualización de software para sus clientes corporativos eliminó un archivo crucial de Windows por error y provocó que millones de computadoras en todo el mundo entraran en un ciclo de reinicio continuo. El problema de McAfee también requirió una solución manual.